모든 CAT tool이 translation memory를 이용할 수 있도록 한다는 것은 그만큼 translation memory가 CAT tool의 핵심이고 번역 능률 향상의 중요한 도구이기 때문입니다. 심지어 다른 기능 없이 translation memory만 따로 떼어낸 독립적인 tool들도 있을 정도입니다(translation memory manager, translation memory tool이라고 불림). 그래서 지난 포스트에 이어 오늘은 CAT tool의 핵심인 translation memory에 대해 좀 더 자세히 살펴보고 관련된 이슈에 대해 논의하도록 하겠습니다.
정의
Translation Memory(이하 TM)는 번역가가 기존의 번역을 재사용할 수 있도록 해 주는 소프트웨어입니다. 소프트웨어이긴 하고 그것을 잘 포장해서 별도의 tool로 만들어 판매하고 있지만 그 핵심을 들여다 보면 실은 소스 문장(사실 유닛 혹은 세그먼트가 맞는 표현임. 아래에서 조금 자세히 설명할 것임)과 그것에 상응하는 타겟 문장을 묶어 놓은 데이터베이스입니다.
TM과 glossary의 차이

Glossary는 특정 회사, 업종, 분야에서만 쓰이는 다소 특수한 용어들을 번역시에 다양하게 번역되거나잘못 번역되는 것을 막기위해 만들어진 자료입니다. 이것은 좀 거창하게 terminology database, termbase, lexicon으로 불려지기도 합니다만 기본적으로 다 같은 것을 가리킵니다. Glossary의 구조도 TM과 매우 유사합니다. 소스 언어의 용어와 타겟 언어의 용어를 연결해 둔 것이지요. 거기에 소스 언어로 남겨둘 용어들(NTBT, not to be translated)이나 용어 정의 등을 담고 있기도 하고요. 이렇게 구조상으로 Glossary와 TM은 대단히 유사한데 그 둘의 차이는 세그먼트의 내용입니다. Glossary는 단어나 구를 다루는 것이고 TM은 문장을 다루는 것이기 때문에 용도가 다릅니다. TM은 주로 번역의 속도를 높여주는 데 반해 Glossary는 특정 용어가 정확하게 번역되는 것에만 용도가 있습니다. Glossary는 안내자 역할을 하고 번역의 모호성을 크게 제거해 주므로 문서의 내용이 특수할수록 그 효용이 빛을 발합니다. 그러나 TM과는 달리 과거 번역을 그대로 이용하여 속도를 높여주는 역할은 하지 못합니다.
TM의 효용
CAT tool에 대한 지난 포스트에서 이미 설명드렸지만 TM은 번역 과정에서 대단히 도움이 됩니다. CAT tool마다 사용 방식이 조금 다르긴 하지만 기본적으로 번역 작업 중에 소스 세그먼트와 정확하게 같거나 비슷한 세그먼트가 나타나면 그것을 바로 재사용할 수 있게 해 주기 때문에 반복이 많은 문서를 번역할 때나 과거에 이미 번역된 문서를 업데이트하는 경우 등에는 대단한 위력을 나타냅니다. 그 외에도 업데이트되는 문서 등에서 일관성을 유지하는 데에도 큰 도움이 됩니다. TM의 효용에 대한 좀 더 자세한 분석은’CAT Tool, 번역가에게 필수인가요?’를 참조하십시오.
관련된 용어와 개념
1) Segmentation과 TM 생성
TM을 이해하기 위해 가장 중요한 개념은 segmentation입니다. TM은 기본적으로 문장 단위의 기억입니다. CAT tool(혹은 TM tool)을 이용하여 문서를 열면 tool은 소스 문서를 개별 문장 단위로 잘게 구분합니다. 이렇게 잘게 구분된 한 단위를 segment라고 합니다. CAT tool이 이렇게 하는 이유는 단어가 아니라 의미 단락별로 구분을 해 주는 것이 나중에 다시 이용하기에 가장 편리하기 때문입니다.
가장 흔한 의미 단위는 당연히 문장이기 때문에 위에서 제가 tm이 문장을 기억하는 것이라고 표현했지만 세그먼트가 늘 문장 단위로만 되어 있는 것은 아닙니다. 예컨대 제목이나 소제목은 문장은 아니지만 중요한 의미 단위이기 때문에 그런 것도 별도의 세그먼트가 되고 텍스트 박스에 있는 내용도 별도의 세그먼트가 됩니다. 항목들이 bullet으로 구분되어 있으면 그 개별 항목들도 각각 세그먼트가 됩니다. 만약 소스 문서가 엑셀 파일인 경우에는 셀을 세그먼트로 파악할지 아니면 셀 안에 있는 개별 문장 등을 세그먼트로 파악할지를 CAT tool이 사용자에게 물어보는데, 그 응답에 따라 한 셀 안의 여러 문장이 하나의 세그먼트가 되기도 하고 한 셀 안의 문장이나 소제목 등이 다 별개의 세그먼트가 되기도 합니다.
CAT tool이 이렇게 세그먼트를 파악하는 과정을 source document analysis라고 하는데 그것이 끝난 뒤에 보면 참 CAT tool이 똑똑하다는 생각을 합니다. 아니, 어쩌면 이렇게 기계 주제에 의미 단위를 잘 파악해 두었을까 하고요. 그런데 CAT tool이 사용하는 요령은 아주 단순합니다. 마침표와 엔터키가 있으면 거기까지를 한 단위로 파악하는 겁니다. (소수점은 마침표로 인식하지 않는 것 같습니다.) 그러니까 제목도 한 세그먼트로 척 잡아내고 문장도 한 세그먼트로 척 잡아내는 겁니다. 기특하지요.
그러나 저렇게 단순한 요령으로 파악하기 때문에 잘못 파악하는 때도 많습니다. 예컨대 U. S. Congress라는 표현이 있으면 멍청하게 “U.”와 “S.”를 각각 하나의 세그먼트로 인식하죠. 멍청이… 그 외에도 etc.가 나오면 뒤에 소문자가 나와도 얄짤 없이 거기까지를 의미 단위로 끊어 놓습니다. 또 PDF를 OCR로 읽어 소스문서를 만든 경우에도 줄 끝마다 manual line break가 들어가니까 다 그까지가 한 단락인 줄 알죠. 이럴 때는 물론 번역가가 인위적으로 세그먼트를 나눌 수 있습니다. 또 원문의 실수로 마침표가 빠진 경우 등에도 세그먼트를 나눌 수 있습니다.
이렇게 해서 소스 문서의 segmentation이 다 되면 그 다음부터 번역가가 번역을 해나감에 따라 자동으로 TM이 생성됩니다. 즉, source segment 하나를 번역하면 그 source segment와 번역된 target segment의 조합이 하나의 TM 단위가 되는 것이지요.
2) Pre-population
위와 같이 생성된 TM은 나중에 CAT tool 안에서 어떤 식으로 재사용될까요? 몇 가지 방법이 있습니다.
- 일단은 TM을 사용하지 않은 채 소스 문서를 열고 개별 세그먼트 안에서 번역가가 TM 사용 여부를 매번 결정하는 방법.
- 소스 문서를 열 때 아예 TM을 사용해서 translation을 시키는 방법.
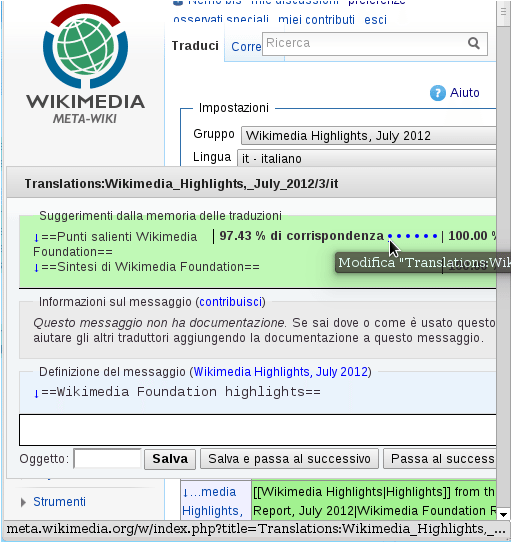
두 번째 방법을 쓸 때는, 일치하는 정도가 몇 퍼센트이면 타겟 세그먼트 안에 TM 내용을 가져다 둘지(이것을 threshold라고 합니다)를 번역가가 지정해 주어야 합니다. 그렇게 threshold를 지정해 주면 문서를 여는 과정에서 CAT tool이 해당 조건에 맞는 TM을 타겟 세그먼트 안으로 가져다 두는데 이것을 pre-population이라고 합니다. 이렇게 pre-populated가 된 세그먼트들을 번역가가 그대로 수용하거나(엔터를 쳐 주거나 다른 세그먼트를 클릭하면 됨) 조금 수정해 주면 됩니다.
3) 반복, 100% 매치, 퍼지 매치
이미 저장되어 있는 TM과 100% 일치하는 세그먼트가 있으면 그 세그먼트는 100% 매치라고 합니다. 이런 세그먼트는 이론적으로는 그대로 수용하면 됩니다. (그러나 실제로는 문맥이 달라서 약간의 수정이 필요할 수도 있습니다.) 정확하게 일치하지는 않지만 저장된 어느 TM 유닛과 많이 비슷한 세그먼트는 퍼지 매치(fuzzy match)라고 합니다. 퍼지 매치는 0%에서 99%까지 표시가 되지만 70% 아래로는 사실상 별 쓸모가 없다고 보시면 됩니다. 하지만 세그먼트 병합이나 분할을 하고 나면 갑자기 일치도가 높아지는 수도 있지요.
매치와는 별개로 반복이란 개념도 중요합니다. 이것은 TM 속에 같은 것이 있는 것과는 별개로, 소스 문서 안에 같은 세그먼트가 여러 개 있는 것을 가리킵니다. 이런 경우는 비록 TM에 저장된 것은 없더라도 하나를 번역하고 나면 나머지 반복되는 세그먼트들은 그 뒤부터 다 100% 매치가 되는 셈입니다.
CAT tool을 써서 소스 문서를 분석하거나 TM pre-translation을 시행하면 위와 같은 반복, 100% 매치(previously translated라고 표현하기도 합니다), 퍼지 매치가 표 하나로 제시됩니다. 이것은 번역가가 해당 문서를 번역하는 데 시간이 얼마나 걸릴지 짐작할 수 있게 하는 중요한 정보입니다. 보통 다음과 같이 제시됩니다.
- Repetitions
- 100% matches
- 95% – 99% matches
- 85% – 94% matches
- 75% – 84% matches
- Unique words (74% or lower)
TM 소유권을 둘러싼 논쟁
이상에서 본 것과 같이 TM은 보관비용도 들지 않는 매우 귀중한 자산이므로 이를 탐내는 사람이 많습니다.
1) 우선 그 TM을 생성한 번역가가 그것을 자신의 자산으로 여깁니다.
2) 번역 에이전시도 그것을 자신의 것으로 주장하는 경우가 있습니다. 이렇게 하는 이유는 반복이나 매치에 대해 번역가에게 할인을 요구하기 위해서입니다.
3) 소스 문서를 생성해 낸 최종 고객에게 TM의 소유권이 있다고 보는 경우도 있습니다. (사실 최종 고객들은 TM이 뭔지도 모르는 경우가 대부분인데, 번역 에이전시들이 영업을 하면서 TM도 제공할 테니 자기 회사를 이용하라고 유혹을 하는 것이지요.)
현재로서는 TM의 소유권에 대한 여러 관련자들의 주장이 정리되지 않은 혼돈스러운 상황입니다. 저는 개인적으로 TM이 번역가의 소유라고 생각합니다. 물론 confidentiality 합의를 해 준 경우에는 그 TM을 다른 상황에서 함부로 사용할 수는 없겠지만 같은 고객을 위한 다른 프로젝트에서는 얼마든지 사용하거나 사용하지 않을 수 있습니다. 게다가 TM 매치가 있다고 해서 그대로 사용할 수 없는 경우도 많으므로 번역가의 수고가 어느 정도는 추가로 들 수가 있고요. 마지막으로 TM을 생성하거나 이용하기 위한 CAT tool을 번역가가 샀으므로(무료 온라인 CAT tool을 사용하는 경우는 이런 주장을 하기가 좀 애매해집니다만), 그것을 사주지 않은 최종 고객이나 번역 에이전시가 TM 소유권을 주장할 근거가 없다고 봅니다. 게다가 제 CAT tool 속에는 TM을 직접 만들어 내기 힘든 상황에서 파일 변환 노력을 통해 만들어 낸 TM도 상당히 많은 편입니다. 그런 TM에 대해 저 아닌 다른 누군가가 소유권을 주장하는 것은 전혀 타당하지 않지요. 저는 앞으로도 기회가 있을 때마다 TM이 번역가의 소유라고 계속 주장해 나갈 생각입니다. 그렇다고 제가 반복과 매치에 대한 할인을 거절한다는 뜻은 아닙니다. 그건 기본 요율(base rate)을 이미 충분히 높게 설정해 둔 상태라면 합리적인 조정을 하는 것은 그리 나쁘지 않습니다. 그런 방식으로 번역 에이전시도 최종 고객에게 할인을 제공할 수 있습니다. (물론 그 할인 부분이 최종 고객에게 전달되는지야 프리랜서 번역가가 알 바는 아닙니다.) 아무튼 앞으로 번역가에게 TM을 요구하는 경우에 TM 제공에 대한 값을 별도로 번역가에게 지급하는 관행이 정착되는 것이 제 바람입니다. 그렇게 되면 에이전시나 최종 고객이 제공하는 TM을 사용해서 번역을 할 때 할인을 해 주는 것도 아깝지도 않고 당연한 일이 되겠지요. 최초로 TM을 생성한 사람은 이미 보상을 받았고 나는 누군가가 만든 TM을 이용하여 빠르게 번역을 할 수 있는 것이니까요. 그러나 언제 그런 날이 올까 싶습니다. 현재로서는 매우 혼돈스러운 상태입니다. 대부분의 최종 고객들은 TM이 뭔지도 모르는 상태이고 에이전시들도 TM을 전혀 신경쓰지 않는 경우가 많습니다. (물론 그건 번역가에게는 좋은 일입니다. 그러나 앞으로 적어도 에이전시들은 TM에 대해 점점 민감해질 수밖에 없지 않을까 싶습니다.) 따라서 TM과 관련된 업계 공통의 관행이 정착되는 것은 당분간 어렵지 않을까 싶습니다.






[…] 있는가 하는 논쟁이 불거지는 것도 바로 그 때문입니다. (TM match가 뭔지는 Translation Memory에 대한 이해라는 포스트에서 이미 설명했으니 다시 설명하지 […]
[…] 있는가 하는 논쟁이 불거지는 것도 바로 그 때문입니다. (TM match가 뭔지는 Translation Memory에 대한 이해와 소유권라는 포스트에서 이미 설명했으니 다시 설명하지 […]