최근에 구글 번역기가 좋아졌다는 이야기 한 번쯤 들어보셨지요? 번역하는 분들이라면 관심을 많이 가지실 주제일 텐데요, 며칠 전에 ‘machine translation(이하 MT)과 NDA’라는 주제로 번역가 B와 번역가 H가 나눈 대화를 대담 형식으로 정리해 보았습니다. (현재 서로 지구 반대편에 있는지라 실제 아래 장소에서 만나 대화를 한 것은 아니고 이메일로 나눈 대화입니다.)

번역가 B(이하 B): 얼마 전에 Fluency의 제작사인 Western Standard로부터 ‘Microsoft machine translation 사용자는 Azure 포털에서 계정을 새로 등록하라’고 안내하는 이메일을 받았습니다. 그런데 등록은 완료했는데 질문이 좀 있어요. Azure라는 것은 클라우드 시스템인 것 같은데, 이것의 명성이나 악소문을 혹시 들으신 것이 있나요? 사실 전 이게 뭐 하는 것인지 아직 잘 모르겠습니다.

번역가 H(이하 H): Azure는 Microsoft사의 클라우드 컴퓨팅 플랫폼입니다. Azure 자체는 단순 플랫폼에 불과하다 보니 마이크로소프트에서 운영한다는 것 이외에 명성이나 악소문이랄 것은 없습니다. 이런 플랫폼 중에 가장 유명한 것으로는 Amazon에서 운영하는 AWS(Amazon Web Services)가 있는데요, 아마존에서 AWS를 만들게 된 계기가 재미있습니다. 처음에 아마존 쇼핑몰에서 블랙 프라이데이나 크리스마스 같은 대목에 통신량을 소화하려고 서버를 증설해 놓았는데, 이게 평소에는 남아돌게 된 것이지요. 그래서 노는 자원을 외부에 어떻게 팔아보려는 의도로 시작한 것이 AWS의 시초라고 합니다. 그런데 지금은 세계 1위의 클라우드 플랫폼이 되어버렸고, 스마트폰에서 사용하시는 앱 중에도 AWS를 사용하는 것이 무척 많습니다. 아무튼, 아마존 웹 서비스가 클라우드 플랫폼 시장에서 1위를 차지하고 있고 Azure는 한참 밑에 있는 2위입니다. Western Standard에서 보낸 이메일 내용을 보면 Microsoft에서 Translator 서비스를 최근에 클라우드 플랫폼, 즉 자사의 Azure로 이전했나 봅니다. 그래서 새로 등록하라고 안내하는 것입니다.
B: 한 달에 2백만 글자를 무료로 사용할 수 있게 한다는데 이 정도면 충분한가요?
H: 단순 계산으로 한 달에 20일 일하는 번역가가 5자로만 이루어져 있는 단어를 번역한다고 가정할 때 매월 20만 단어, 하루에 2만 단어를 MT에 적용할 수 있는 분량입니다. 물론 번역가에 따라서는 이 정도의 양이 부족한 경우도 있겠지만, 5자보다 짧은 단어도 많고 모든 원문에 MT를 적용하지 않는다면야 쓰시기에 충분할 듯합니다. (혹시 이것으로 부족하다면 그 달만 다른 MT엔진으로 설정을 바꾸어 두었다가 다음 달 초에 원래대로 되돌리면 됩니다.)
B: 저는 요즘 MT를 쓸 기회가 그리 많지 않은데 H씨는 좀 쓰시나요?
H: 저도 좀 더 적극적으로 사용해 보고 싶습니다만, 막상 번역 일에 MT를 쓸 기회는 썩 많지 않은 것 같습니다. 다른 이유보다는 NDA 때문에 그렇습니다. 물론 NDA에 구애받지 않고 사용할 수 있는 MT 엔진도 있으나, 대표적으로 S사에서 제공하는 MT 엔진은 경험상 영 품질이 좋지 않았습니다. 물론 지금도 학습을 통해 계속 개선하고 있겠지만, 기본 알고리즘을 바꾸지 않는다면야 큰 기대는 되지 않습니다. 적어도 MT 분야에서는 소위 ‘넘사벽’이라고 할 수 있는 구글이 떡 버티고 있으니까요. 구글 번역기 이야기는 밑에서 다시 이어가겠습니다. 아무튼 요즘은 에이전시에서 작업 파일에 MT를 한 번 적용한 다음에 파일을 보내줄 때가 많은데, 막상 내용을 살펴보면 재번역해야 하는 수준이 대부분이었습니다. 모 에이전시에서 보내온 특정 프로젝트에서 MT 결과가 제법 훌륭해서 감탄한 기억이 있는데요, 막상 또 제가 해당 회사의 MT 제품을 써 보면 성능이 시원찮더군요. 에이전시가 사용하는 MT 엔진과 번역가에게 대여하는 MT 엔진 성능이 다를 수 있겠다는 의심이 살짝 들었던 적이 있습니다.
B: 그랬군요. 그렇다면 NDA란 정확하게 무엇인가요?

H: 서비스 수준 계약서/협약서를 뜻하는 SLA는 많이 들어보셨을 텐데요, 분야에 따라서는 NDA라는 말을 처음 들어보는 번역가도 계실 것입니다. NDA는 ‘Non-Disclosure Agreement’의 약어로 우리말로는 비밀(기밀) 유지 계약서 정도로 옮길 수 있습니다. 세부 내용은 계약서마다 다를 수 있지만, 말 그대로 번역하면서 알게 된 제반 자료와 정보에 대해 비밀을 유지하도록 요구하는 계약서로 생각하시면 무리가 없을 듯합니다. ‘왜 나를 못 믿고 이런 걸 요구하나?’라며 기분 나쁘게 생각하실 수도 있지만, 번역을 의뢰하는 고객은 중요한 내부 문서가 외부로 유출되면 자칫 큰 문제가 발생할 수도 있으므로 이런 일을 사전에 방지할 필요가 있습니다. 비단 번역이 아니더라도 계약 시에 비밀 유지 계약서를 함께 쓰는 일이 많지요. 그런데 예전에는 의도적으로 NDA를 어기는 일이 문제가 되었다면, MT 사용이 보편화된 지금은 자신도 모르게 NDA를 위반할 수 있게 되었습니다.
B: 그렇다면 Microsoft Azure를 통해 기계번역을 사용하는 것도 서버에 원문이 남게 되나요? 아마 그렇겠죠? 그렇다면 NDA를 어기지 않고 기계 번역을 사용할 수 있는 방법이 있나요?
H: 말씀대로 서버에 원문이 남을 수 있습니다. Microsoft의 서비스 계약과 Microsoft Translator의 개인 정보 취급 방침을 살펴보면 아래와 같은 내용이 있습니다.
Microsoft Services Agreement:
“To the extent necessary to provide the Services to you and others, to protect you and the Services, and to improve Microsoft products and services, you grant to Microsoft a worldwide and royalty-free intellectual property license to use Your Content, for example, to make copies of, retain, transmit, reformat, display, and distribute via communication tools Your Content on the Services. If you publish Your Content in areas of the Service where it is available broadly online without restrictions, Your Content may appear in demonstrations or materials that promote the Service.” (Published: July 15, 2016)
“본 서비스를 귀하 및 다른 사람에게 제공하고, 귀하 및 본 서비스를 보호하고, Microsoft 제품 및 서비스를 개선하는 데 필요한 범위 내에서 귀하는 Microsoft에게 귀하의 콘텐츠를 사용(예: 본 서비스에서 커뮤니케이션 도구를 통해 귀하의 콘텐츠의 복사본을 만들고, 귀하의 콘텐츠를 보관, 전송, 서식 변경, 표시 및 배포)할 수 있는 전세계 무상 지적 재산권 라이선스를 허여합니다. 귀하가 제한 없이 온라인상에서 광범위하게 사용할 수 있는 본 서비스의 영역에 귀하의 콘텐츠를 게시하는 경우 귀하의 콘텐츠는 본 서비스를 판촉하는 데모 또는 자료에 나타날 수 있습니다.” (발행일: 2016년 7월 15일)
Translator Privacy Statement:
“The text we use to improve Translator is limited to a sample of not more than 10% of randomly selected, non-consecutive sentences from the text you submit, and we mask or delete numeric strings of characters and email addresses that may be present in the samples of text. he portions of text that we do not use to improve Translator are deleted within 48 hours after they are no longer required to provide your translation. If Translator is embedded within another service or product, we may group together all text samples that come from that service or product, but we do not store them with any identifiers associated with specific users.
…
If you subscribe to the Microsoft Translator API with a monthly volume of 250 million characters or more, you may request to have logging turned off for the text you submit to Microsoft Translator by submitting a request using the process detailed at https://www.microsoft.com/en-us/translator/notrace.aspx.” (Last Updated: March 2016)
“Microsoft Translator는 사용자가 제출하는 텍스트, 이미지 및 음성 데이터뿐 아니라 사용자가 Translator 서비스에 액세스하는 방법에 대한 정보(예: 운영 체제 정보, 브라우저 유형 및 언어)도 수집하고 사용합니다. Microsoft는 사용자 환경의 개선 및 개인 설정을 비롯한 Translator 서비스를 제공하기 위해 사용자의 데이터를 수집하고 사용합니다.
…
월간 사용량 2억 5천만 자 이상의 Microsoft Translator API를 구독하는 경우 www.microsoft.com/translator/notrace.aspx에 설명된 프로세스를 통해 요청하여 Microsoft Translator에 제출하는 텍스트에 대해 로깅을 해제하도록 요청할 수 있습니다.” (마지막 업데이트 날짜: 2016년 11월)
Translator Privacy Statement에서는 특히 번역에 관해 구체적인 방침을 언급하고 있습니다. 제가 찾아본 바로는 영어 사이트와 한국어 사이트의 구성이 달라 내용이 1:1로 대응하지는 않았습니다만, 큰 줄기에서 보면 대동소이합니다. 아무튼 이렇게 기록되는 것이 싫다면 로깅 해제 요청을 해야 하는데, 그러려면 매월 2억 5천만 자 이상을 처리하는 플랜을 구독해야 하고, 이게 약 2,000불이나 한다고 합니다. 프리랜서 번역가에게는 너무 과하지요. 내친김에 구글의 약관도 살펴볼까요? 구글 서비스를 이용하는 것은 기본적으로 아래 내용에 동의하는 것이라고 합니다.
Google Terms of Service:
“When you upload, submit, store, send or receive content to or through our Services, you give Google (and those we work with) a worldwide license to use, host, store, reproduce, modify, create derivative works (such as those resulting from translations, adaptations or other changes we make so that your content works better with our Services), communicate, publish, publicly perform, publicly display and distribute suc h content.” (Google Terms of Service – 14 April 2014)
“귀하가 콘텐츠를 Google 서비스로 또는 이를 통해 업로드, 제출, 저장, 전송 또는 수신하는 경우 귀하는 Google(및 Google의 협력사)이 이러한 콘텐츠를 사용, 저장, 복제, 수정, 이차적 저작물(귀하의 콘텐츠가 Google 서비스와 더 잘 작동하도록 Google이 생성하는 번역본, 개작본, 또는 수정본으로 인해 발생되는 것) 제작, 전달, 공개, 공개적으로 실연, 공개적으로 게시 및 배포할 수 있는 전 세계적인 라이선스를 제공하게 됩니다.” (최종 수정 날짜: 2014년 4월 14일)
그리고 구글의 책임을 규정한 아래 부분도 한 번 보실 필요가 있습니다.
“WHEN PERMITTED BY LAW, GOOGLE, AND GOOGLE’S SUPPLIERS AND DISTRIBUTORS, WILL NOT BE RESPONSIBLE FOR LOST PROFITS, REVENUES, OR DATA, FINANCIAL LOSSES OR INDIRECT, SPECIAL, CONSEQUENTIAL, EXEMPLARY, OR PUNITIVE DAMAGES.”
“법률상 허용되는 경우, Google, Google의 공급자 및 판매자는 일실이익, 일실수입, 망실자료, 재무적 손실, 간접 손해, 특별 손해, 결과적 손해, 징계적 손해, 또는 징벌적 손해에 대한 책임을 지지 않습니다.”
요컨대 번역가가 구글 번역기를 이용한다는 것은 전송한 세그먼트를 서버에 저장하는 것에 동의하는 것이고, 이로 인해 발생할 수 있는 문제에 대해 구글은 책임을 지지 않는다는 것을 알 수 있습니다. 만약 구글 번역 서버에서 고객의 기밀 콘텐츠가 발견되었다면 구글이 아닌 번역가만 책임을 져야 한다는 뜻이지요. 이외에 오픈소스의 non-public MT 엔진도 여럿 있습니다만, 구글 번역기나 마이크로소프트의 번역기에 비하면 사용자 수가 현저히 적다 보니 아무래도 성능이 좀 떨어집니다. 이런 문제를 해결하려고 구글 같은 서버에 세그먼트를 보내기 전에 문장에 포함된 이름, 고유명사, 위치, 숫자 같은 정보를 자동으로 바꾸고, 나중에 구글 서버에서 반환된 세그먼트를 원래 세그먼트로 돌려주는 솔루션을 개발하는 회사도 있다고 하더군요. 그리고 매월 비용을 지불하는 유료 MT 엔진은 자사 서버로 전송되는 콘텐츠가 안전하다고 광고하곤 합니다. 그러나 대부분 에이전시에서는 구글 번역뿐만이 아닌 온라인 번역 서비스를 일절 사용하지 않도록 요구하기 때문에 NDA를 어기지 않고 MT를 사용하는 것은 참 어렵습니다. 물론 NDA도 세세한 내용은 다르니 가능할 수도 있겠지만요.
B: MT를 쓰신다면 어느 것을 주로 쓰시나요? 혹시 여러 개 중에 더 나은 것이 있던가요? 구글이 나아졌다는 얘기가 있던데 혹시 최근에 사용해 본 경험이 있으신가요?
H: 네, 개중 성능이 뛰어난 것은 역시 구글 번역입니다. 작년에 구글에서 차세대 인공신경망 기술을 적용하면서 성능이 대폭 향상되었습니다. 지금 이 순간에도 나아지고 있는 중이겠지요. 구글은 “지난 10년 동안의 발전보다 더 큰 발전을 한 번에 이뤄냈다”고 자평하더군요. 네이버에서 공개한 인공신경망 번역기도 제법 괜찮았습니다. 저도 재미로 잠깐 비교해 봤는데, 예전의 말도 안 되는 번역기를 생각해 보면 둘 다 성능이 정말 좋아졌습니다. 예상했던 대로 투입할 소스와 타겟 자원이 풍부한 기술이나 법률 분야, 그리고 길이가 짧은 문장은 사람이 옮긴 것과 비슷하고 의미를 파악하는 데 큰 무리가 없었습니다. 그렇지만 글이 길어지거나 난해한 분야는 아직 미흡하다는 느낌을 많이 받았습니다. 자세히 보면 오역이나 오류도 여럿 있었고요. 일을 하면서 가장 써 보고 싶은 건 구글 번역기지만, 앞서 말씀드린 것처럼 일단 서버에 내용이 기록되는 것이다 보니 취미로 사용해 보는 데 만족해야 할 것 같습니다. 지난 달에 뉴욕타임스에 새로운 구글 번역기를 집중 분석한 기사인 “The Great A.I. Awakening”가 한동안 화제였는데요, 좀 길긴 하지만 기술적인 부분은 건너뛰고서라도 한 번 읽어볼 만합니다. 한국어 버전은 여기에서 읽으실 수 있습니다. 그리고 여러 번역기의 한국어 성능을 비교해 보는 분들도 종종 보입니다.
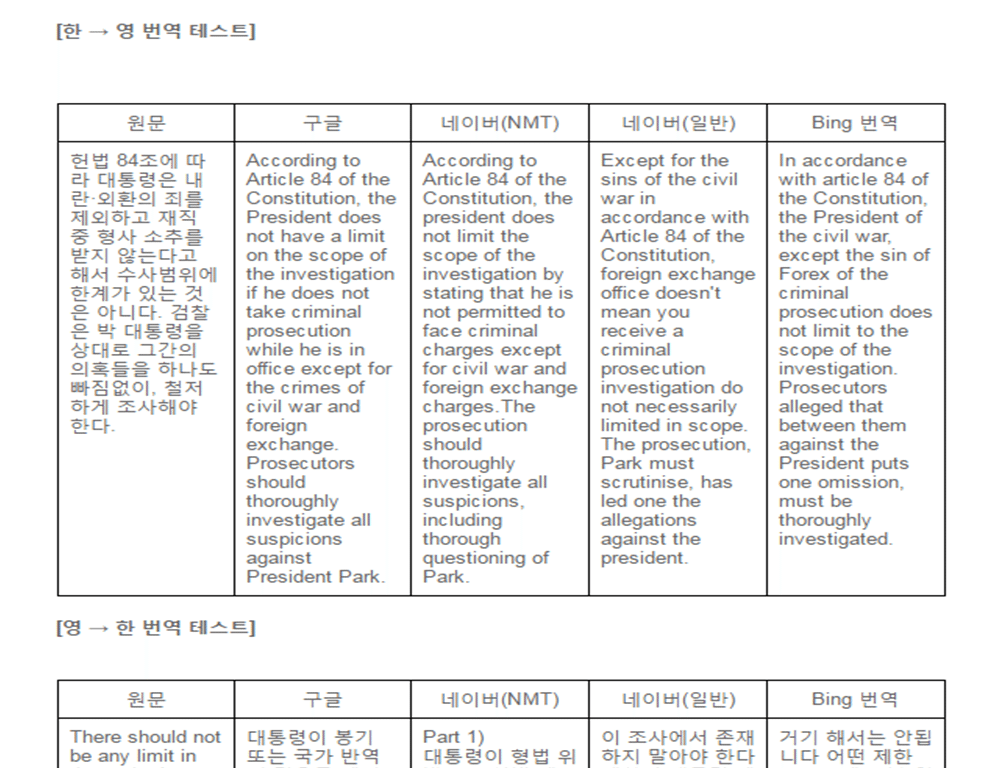
B: MT를 비교한 글을 살펴보니, 한국어와 관련해서는 한영이나 영한이나 아직 쓸모없기는 마찬가지라고 봅니다. 제가 보기에는 구글번역도 한참 멀었다고 생각합니다. 몇 년 있으면 좀 나아지려나요?
H: 네, 재미 삼아 돌려보는 건 몰라도 실제로 소용이 있으려면 아직 한참 멀었습니다. 그렇지만 불과 이삼 년 전만 해도 학자들이 기계가 바둑을 못 따라잡을 것이라고 했던 것처럼 번역도 차차 나아지지 않을까요. 영향을 덜 받는 분야도 있겠지만 적어도 컴퓨터, IT 등을 위시한 기술 분야에서는 위기감이 팽배합니다. 데이터 사이언티스트로 일하시는 분이 “예전 같으면 번역가에게 맡겼을 일이 아예 없어졌다“라고 언급하신 글을 읽은 적이 있는데, 저도 내용에 대체로 동의하는 편입니다. 번역가라는 직업이 당장 사라지지는 않을 것이고 최상급의 번역가는 항상 필요하겠지만, 기존 번역 시장의 파이를 MT가 상당 부분 잠식하게 될 것 같습니다.
여담으로 MT 사용에 대해서는 번역가들 사이에서도 해묵은 논쟁이 분분합니다. Gmail로 번역 프로젝트를 받기만 해도 기밀 정보를 유출하는 것이라고 주장하는 사람도 있고, MT 자체는 문제가 아니지만 구글 정책이 문제라는 사람, 자신은 기계에 의존하지 않고 수십 년 동안 번역을 해 온 프로 번역가로서 MT 같은 것은 수준 낮은 번역가만 사용하는 것이라는 사람도 있습니다. 그러나 이미 ‘Machine Translation Evaluator’ 같은 새로운 직업이 엄존하는 이상, 현시대를 살아가는 번역가라면 MT 기술의 발전에 대해서도 어느 정도 알고 있어야 한다고 생각합니다. 저는 MT도 CAT tool처럼 하나의 도구라고 생각한다면 잘 활용해서 써먹는 것이 좋다는 입장입니다.
B: 마지막으로, MT를 사용하다 NDA를 위반하지 않으려면 어떻게 해야 할까요?
H: 너무 뻔한 말씀을 드리는 것 같지만 주의에 주의를 거듭하십시오. 제가 거래하던 에이전시에서는 어떤 번역가가 대놓고 구글 번역기를 사용하여 소동이 벌어졌던 적이 있습니다. 자칫 잘못되면 법적으로 책임을 져야 할 수 있습니다. MT를 사용하려 한다면 번역할 내용에 중요한 정보가 없더라도 반드시 사전에 고객과 협의하십시오. (Trados Studio처럼 xliff 파일에 구글 번역기 사용이 기록되는 CAT tool도 있습니다.) 대부분의 고객은 허락하지 않겠지만, MT가 인간 번역가에게 도움을 줄 수 있음을 이해하는 고객이 있을 수도 있습니다.
B: 이렇게 대화를 나누고 나니 잘 몰랐던 부분이 환하게 밝아지는 것 같습니다. 정말 감사드립니다. 이 내용을 정리해서 포스트로 올리면 다른 분들께도 도움이 될 것 같습니다.
H: 별 말씀을요. 저도 즐거웠습니다. 제가 내용을 정리해 보겠습니다.